


Are data scientists erasing domain experts? Part II
A great paper by Elmira van den Broek, Anastasia Sergeeva, and Marleen Huysman suggests no. The big-picture answer is complicated and depends on what you mean by "domain experts" and "erasing."

In Part I of this series, I laid out some of the background for the debate on the relationship between data scientists and domain experts. My point was that outcomes vary across sectors and domains and that the term “domain expert” seems to be applied with such a broad brush that it does not have analytical cachet. In today’s post, I want to summarize one of my favorite studies one this issue (what is domain expertise really?) and suggest some takeaways.
The study in question is by Elmira van den Broek, Anastasia Sergeeva, and Marleen Huysman and it is titled “When the Machine Meets the Expert: An Ethnography of Developing AI for Hiring.” The authors were able to—miraculously! in a way that only business school professors can—document the entire process of designing and implementing a hiring algorithm (i.e., an algorithm that would take some input and then output a score for a candidate being considered for hiring). Their fieldwork covered the entire process: from the data scientists (and others) designing the algorithm at a startup to how the product worked out when it was shipped to the customer.
The key takeaway: the data scientists had to constantly face a tension between designing an algorithm that was completely independent of the setting it was supposed to be used in and trying to find a way to get it to work in that actual setting. Or as the authors put it: the algorithm designers faced a “new tension between maintaining independence from domain experts so they can uphold their claim to superior knowledge and maintaining relevance to the domain they serve.” They solved it ultimately by incorporating the domain experts into their workflow, creating a new “hybrid practice that relied on a combination of [machine learning] and domain expertise.” In the process, both groups, the data scientists and the domain experts, to reflect on their own practices.
But I think the study tells us quite a few things that the authors don’t get to discuss in the paper, obviously for reasons of space. In no particular order, it tells us: (1) the domain experts here were also clients. As clients, they obviously got to have a say on how the product should be designed. (2) There are many different domain experts relevant to a problem but only some domain experts actually get incorporated into the process. I will argue here that the experts who were incorporated into the design process were actually meta-experts who had their own version of domain-independence, just like the data scientists.
This post will have three sections.
Section 1 will narrate the story that the authors tell in their paper about how the hiring algorithm was designed and implemented. I will go into this story in some detail because there are so many telling details and it is well worth your time. I encourage everyone to actually read the paper and hear the story in the authors’ own words.
Section 2 will probe deeper into the story and make some points about the domain experts who make the most appearances in the story: the HR professionals. What is HR? HR, it turns out, is its own kind of domain-independent field of expertise, not unlike data science.
Section 3 will explore the question of who actually “won” this contest between experts. I will argue that the experts who seem to have gained the most from this are the HR professionals. But I will show that the delimitation of domain experts is fraught exercise because there are many domains at play in any activity. One particular domain here that does get empowered is psychology even if it is at the expense of psychologists.
1. NeuroYou designs a hiring algorithm
NeuroYou (pseudonym) is a European AI startup that specializes in making algorithms for hiring. It develops something like gamified tests; when people apply for a job, rather than submitting their resumes, they play these games and their performance in these games can be used to estimate some of their characteristics that are relevant to their job performance.
Now, typically, the way that the job process works for any company—so any client of NeuroYou's—would be something like this: job seekers send in their resumes, cover letters, and perhaps some standardized tests. Those materials are assessed by the Human Resources (HR) team which then makes a shortlist of people to interview. These people are then interviewed by senior managers (i.e., non-HR people whose teams the new employees will be joining). Once these managers have selected a candidate, HR will send an offer to that candidate.
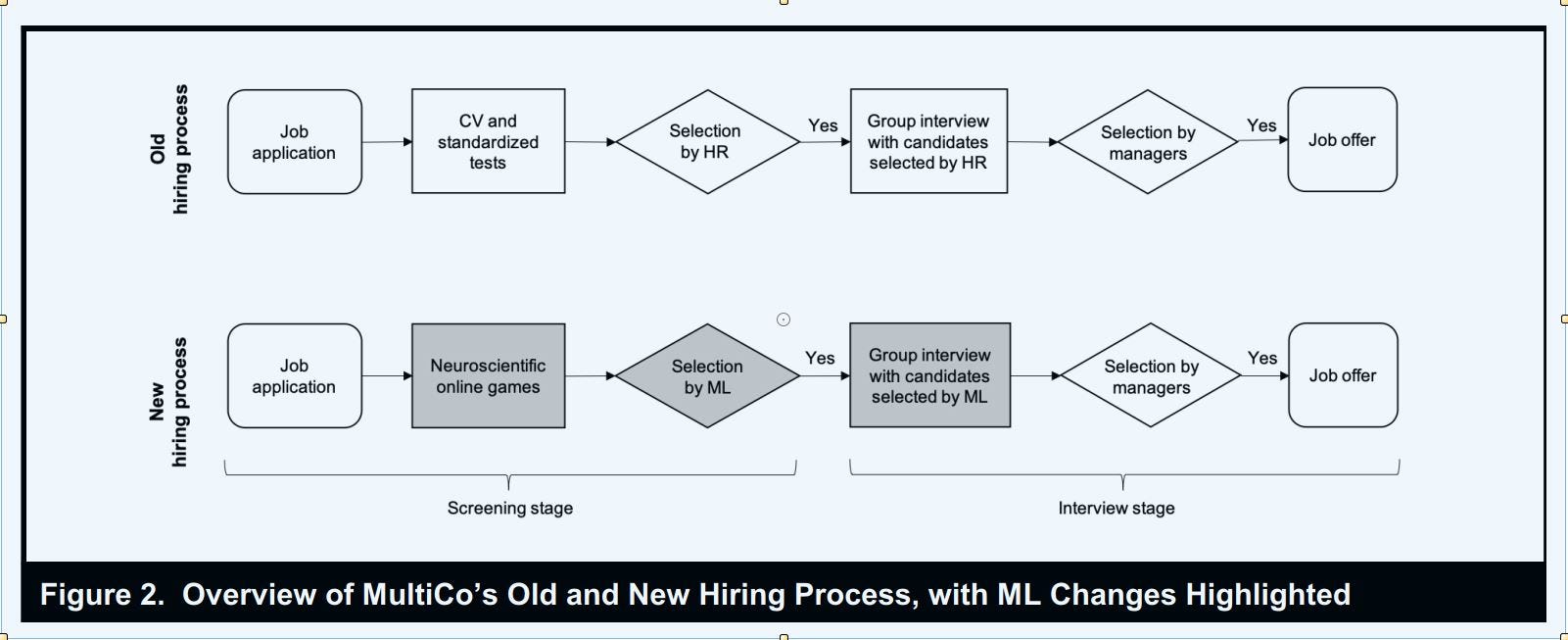
What NeuroYou hoped to do was to use its games and its ML in that first stage of hiring. Instead of the candidates submitting their CVs, they would play NeuroYou's games. And then, NeuroYou would use sophisticated ML algorithms to classify, based on a candidate's performance in the game, whether this was a suitable job candidate or not (see the figure above).
NeuroYou's big break came when they secured a client who agreed to try this out, a big global company called MultiCo, “one of the world’s largest fast-moving consumer goods (FMCG) companies, with almost 200,000 employees in more than 50 countries." Until they had secured a client who would try out the technology in practice, the technology was, in a sense, useless.
But getting a client to try out NeuroYou’s algorithms changed the contours of the problem NeuroYou was trying to solve. Until then, what NeuroYou was doing was supposed to be domain-nonspecific; the whole point was that the hiring algorithm should work across all settings. But now, it was imperative that the hiring algorithm work in this particular setting, otherwise, bye bye client and revenue. How NeuroYou’s designers balanced the general and the particular forms the gist of the paper with the paper emphasizing that the pursuit of the particular took precedence for the data scientists over the pursuit of the general.
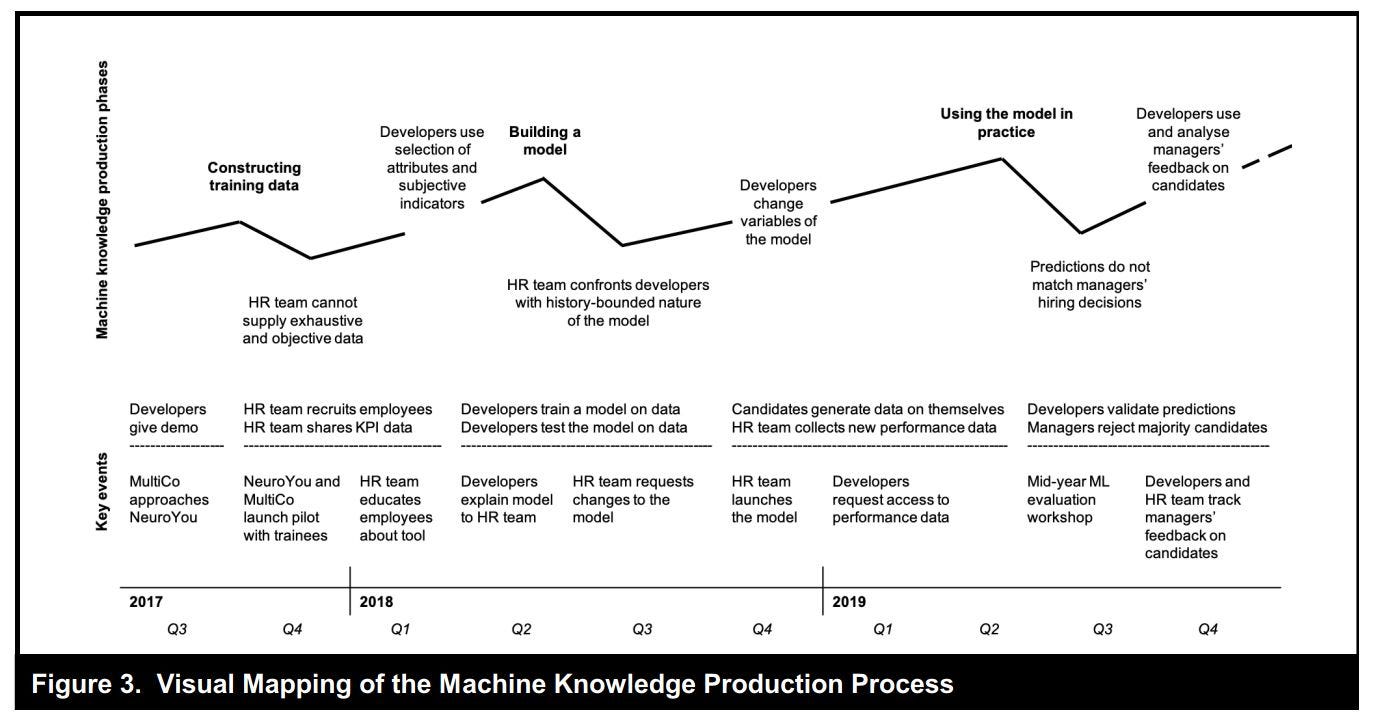
But what happened exactly? The authors talk of three stages of development which correspond to some idealized way of how algorithm development works or is supposed to work: "construct training data," "build the model," and "use the model in practice." In each of these there were phases when the data scientists first excluded and then included the knowledge of the domain experts (in this case, mostly the HR team) and also phases where each group, the data scientists and the domain experts, were forced to grapple with their own practices. (The figure above summarizes the three stages and what happened in each stage.)
In step 1, constructing training data, the data scientists initially "started collecting a dataset of pairs of employee attributes and performance outcomes with which to train the algorithm" (p. 1568). But to actually do this analysis, would mean that existing MultiCo employees would have to play the games they had constructed. The data scientists quickly realized that this was asking too much from the employees. At the same time, the HR employees pushed back on some of the attributes that the developers were putting in their model because those attributes, e.g. the vocabulary possessed by a particular candidate, did not seem to them to be relevant.
This impasse was solved by the data scientists “including domain expertise”: essentially the data scientists from NeuroYou and the HR people from MultiCo got together to think about what makes for a good employee. Ultimately, the data scientists decided to use the performance reviews of employees as their benchmark for evaluating good employees. But there was a big discussion on what makes a good employee that even made some of the HR managers reflect on their metrics.
In step 2, creating the model, the developers first started developing classifiers to see what attributes of people linked to their performance. They chose simpler algorithms because they knew they had to interpret them for their clients.
The model that the developers created with this approach genuinely surprised the HR team. For instance, they showed that the traits associated with successful employees were more about sociality--characteristics like "energy" and "assertiveness"--than about IQ which made the HR team rethink what they often looked for in candidates (p. 1570).
But the HR people also did not care for some of the insights that the algorithm came up with because they felt that it showed areas where they could improve. So the HR people told the developers not to make the algorithm just replicate what was happening; they wanted the algorithm to be forward, rather than backward, looking.
For instance, the algorithm showed a correlation that employees who did not like working conditions were often also people who did not perform well. This presented a causality dilemma: is it the working conditions that brought on the bad performance or is it the bad performance that makes them dislike the working conditions? The HR staff felt that the algorithm, when it produced hiring scores, should not prioritize the correlation between job performance and desire for work-life balance. (I'm sure they were also afraid of being sued.) The HR people also pushed back against the way the algorithm showed that cognitive skills were not important; they said that they were not important now but they could be important in the future when people in sales would work more with technology.
Once again, to solve this impasse, the data scientists started consulting with the HR workers on what their idea of a good performing employee was like and started to incorporate this into their model. As a result, “the model increasingly converged with how [the HR people] judged candidates.”
The last step, step 3, was using the model in actual hiring. The model was launched and deployed for a pool of 10000 candidates. The candidates played 15 games that generated data for the algorithm to classify and score. Based on its score, the model selected 4000 of those candidates for the HR team to look at. This was the whole goal because the process was now much more efficient than when it was done just by the HR team.
But there was a catch. When some (many?) of these high-scoring candidates were interviewed by the hiring managers (the people who would actually be managing them, not the HR professionals), they were almost immediately rejected, especially some “candidates that the algorithm predicted to be exceptional fits” (p. 1571). The paper does not quite say how much the managers disagreed with the metrics but clearly did not like the candidates enough to hire them.
For the data scientists, this was a bad outcome. But the HR staff found this situation problematic as well because they didn't want to seem as if the algorithm was wasting the managers' time.
Once again, there was an impasse. To solve the impasse, the data scientists now had to go talk to senior managers who were actually doing the hiring (not just the HR people). This was drawing the data scientists more and more away from how their desire to stay independent of the practical aspects of hiring. The authors’ words here are pretty telling:
Although [the data scientists] initially aimed to stay far away from how hiring was actually performed in practice, the developers realized that, if they wanted the managers to take up the algorithmic predictions, they would have to dig deeper into managers’ reasoning for selecting candidates during the group interview.
So what did they do? With the help of the HR people, they created a new tool for the managers to write comments documenting their rationale for hiring decisions. In a way, they were changing one of the core things in managerial practice by forcing managers to document their decision-making.
But once again, to get the algorithm accepted, the data scientists had to show that it would do something beyond just duplicating the managers’ decision-making process. It had to help these managers improve their process, perhaps by revealing some flaw or bias in the process.
When the data scientists mined these reports by managers, they reported to HR that “managers seemed to suffer from an “anchoring bias,” that is, a tendency to use an outstanding candidate as a parameter by which to evaluate all others” (p. 1572). This advice was appreciated by HR (we don’t quite hear the managers’ reactions) who had this to say:
I am happy that you did this analysis. It’s too early to say what we will do with this knowledge, but it allows us to look differently at the process and go back to the exercise of finding out, if we are looking to find the best talent, how do we do it? (Field notes, client meeting) (p. 1573).
And it is at this point that the paper ends. We do not get to see how this feedback was incorporated into the algorithm exactly. We also do not get to hear if it worked: whether the senior managers were now happy with the scores that the algorithm gave them for the people they interviewed.
Still, the authors make two points. First, while clearly the data scientists began with the goal of being domain-independent, they tended to get more and more involved with the domain and make their solutions narrowly tailored to contexts by actively consulting with the domain experts, thus creating a “hybrid” approach. Second, both the data scientists and the domain experts discovered new things about their respective practices and were forced to reflect on what they did.
2. HR professionals as domain experts on the client side who do domain-nonspecific work
It’s useful, at this point, to step back and think carefully about the multi-faceted story the authors tell in this paper and go beyond the specific point the authors make. I want to note two things:
The domain experts most involved in the algorithm development—who worked most closely with the data scientists—are the HR personnel working for MultiCo. This is important because the work that the HR professionals do in the hiring process is itself domain-nonspecific: they weed out the good candidates from bad based on general (who is a good employee?), rather than specific (who is a good employee for this job?), criteria.
These domain experts are clients of NeuroYou which means that they are in a position of power relative to the data scientists because they control the purse strings.
Let’s start from point 1. Who are HR professionals? What do they do? What is their history?
This piece is obviously not the place to provide a full history. But the predecessors of HR departments date back to the emergence of the managerial corporation in the late nineteenth century, as documented by historians like Alfred Chandler and Joanne Yates. With the emergence of large-scale technologies like railways, telegraph, telephones, and electricity grids, corporations expanded across space. Such corporations now had to create elaborate hierarchies of employees and clear rules so that each employee was carrying out his or her task in as standardized way as possible so that every employee was replaceable. The result was the emergence of organizational communications that standardized jobs, especially handbooks and reports that went down and up the hierarchy respectively.
It is this that led to the emergence of the first “personnel management” departments whose job was to make sure that employees were happy and organizations were efficient. Over time, “personnel management” morphed into “human resource management.” In the 1970s, as the sociologist Frank Dobbin has documented, HR bureaucracies invented wholly new forms of “diversity management” practices as they constructed concrete organizational procedures to implement the vague non-discrimination provisions of the Civil Rights Act.1
We can see the importance of HR in the institutional processes of MultiCo. HR takes the lead in advertising for jobs and carrying out the first screening of candidates before the actual managers step in to do the interviewing (see figure 2 at the top).
But here’s the rub: HR’s screening of candidates is itself domain-nonspecific. The HR workers at MultiCo are not the actual supervisors of the hired employee. Instead, their job is to construct some general criteria that separates good employees from bad and seek to apply those criteria to any and all positions that the firm seeks to hire.
Why did the HR professionals at MultiCo even want to try NeuroYou’s algorithmic product? After all, doesn’t the NeuroYou algorithm, at least theoretically, endanger a jurisdiction that HR has laid claim to: the first pass of the hiring process?
To their credit, the authors asked this question to the MultiCo HR team. It turns out that the HR people had a pipeline bottleneck and wished to make the hiring process faster. The authors tell us that:
Tim, MultiCo’s HR innovation manager, approached NeuroYou because he believed hiring could be much faster and more efficient, especially when the company had to select large groups of candidates, as they did for its trainee programs. (p. 1566).
Of course, there are several things here that could be happening below the surface. MultiCo's HR could have been facing pressure from MultiCo's leadership and rather than the leadership undercutting them in this quest for efficiency in hiring, the HR managers thought they should be pro-active and invest in the process themselves even if it meant bringing in an algorithm that would give them slightly less autonomy. The authors gesture to this at the end of the article by pointing out that “HR professionals […] suffer[..] from a low professional status” and have therefore “framed AI as an opportunity to reach professional respectability.”
But what’s also clear is that the HR professionals could invoke the service of the algorithm because their task was itself domain-nonspecific; the expertise of HR professionals is a kind of meta-expertise.
I use the term “meta-expertise” here in the sense that the legal scholar Frank Pasquale uses it in his article “Battle of the Experts: The strange career of meta-expertise.” Meta-expertise, according to Pasquale, is about “the development of standardized and specialized algorithmic and quantitative methods that trans-substantively evaluate outcomes in particular experts’ fields.”2 Meta-experts, as defined here, are evaluating other experts’ work in a standardized format; their evaluation is “trans-substantive” rather than substantive, which is to say, they are evaluating other experts work in terms that are more general than the “domain” in which those experts work.
In the article, Pasquale’s target are algorithmic metrics from Silicon Valley and the experts who build them (i.e., data scientists) but the definition should make it clear that HR professionals are also quintessential meta-experts here.
To sum up point 1 then, the experts who end up both summoning the data scientists and then also collaborating with them the most turn out to be meta-experts themselves. One speculative conclusion to draw from this (which I hope to return to in future posts) is that the experts who are competing with data scientists tend to often be meta-experts themselves.
Which leads us to point 2. The collaboration between the data scientists and the HR professionals is only possible because the HR professionals sit in MultiCo which is NeuroYou’s client. As clients, they hold the purse strings and they get to have a say in evaluating whether the algorithm “works” or not. In other words, the HR professionals serve as the main “voice” from the client side.
What’s interesting is that they also serve as the “voice” of the data scientists within MultiCo. In step 3, when the data scientists realized that they would need to work with the actual managers to figure out what criteria they use for hiring, it is the HR professionals they turn to for advice. When they eventually build a tool that managers can enter their rationales for a particular hiring decision, this tool is announced to the managers by the HR professionals. The authors include the full text of the announcement in their paper and it is worth quoting in full:
There is a big change I have introduced here, which is to write comments in the [NeuroYou] tool. Previously, we only voted yes or no. This time I also ask you to put comments in the tool for two reasons. First, those comments are the most valuable feedback to candidates. Thinking about the candidates’ experience, this is the best they can take out of the experience, that our highest leadership has taken the time to give them comments. Another thing that’s important is to challenge ourselves about what we need and want from the candidates. The more you put in the comments, the more help you provide me in knowing what you expect from the candidates. We want to search for candidates that fit your criteria. [Announcement from HR professional to managers]
Notice what is going on here in this announcement. The HR professional doesn't quite say outright that the goal of these notes is to provide training data to NeuroYou. Instead, she frames it as something good but for other reasons: (a) candidates will get feedback and this will be important to them especially if they get rejected. (b) Writing down what our standards are is useful just as a reflection exercise for managers. (c) It will be useful to HR itself in narrowing down candidates to give to the senior managers. In other words, these comments serve not just the data scientists but HR professionals themselves because these are both meta-experts.
So to conclude: the domain experts who play the most role in the development of the algorithm are (a) meta-experts, and (b) situated on the client side.
3. Who’s taking over?
So are data scientists erasing domain experts? Who’s taking over?
Almost certainly, I can’t see any interpretation of the paper which suggests that the data scientists are taking over, at least in this case. If anything, it is the domain experts, the HR professionals, who seem to have ended up having a lot of influence on the development of the algorithm. In addition to achieving their goal of efficiency, they have become co-developers of the algorithm and maintainers of the algorithm as well. It’s true they ceded some control to the algorithm but this is amply compensated by their inputs in its development and their role in its maintenence.
But if we zoom back far enough, there are other domain experts operating in the fringes who do not take center-stage in the article: (a) the managers at MultiCo who make the final decision on hiring the prospective candidate in the interview stage (see figure 2 at the top), and (b) the psychologists at NeuroYou and beyond who create the psychological knowledge that makes the NeuroYou’s product possible. Are they being erased or is there something else happening?
Let’s start with (a). These managers usually only come in at the second stage of the hiring process. They were co-opted into the algorithm development when the data scientists built a tool that captured the managers’ interactions as they made the hiring decision.
One could argue that these managers were empowered because their considerations for hiring were built into the algorithm. However, it does not seem like they got to meet with the data scientists to give their input (and it’s not clear that they wanted to or had the time to do so). Instead, their inputs were captured through a tool that was designed by the data scientists; which means, in effect, that they were co-opted into the algorithm development process as users. (It’s ultimately unclear if they liked the new algorithm because the paper basically stops at this point in the story.)
Now let me take a step beyond what is warranted through a reading of the paper. Imagine that there is a conflict between the two groups of domain experts within MultiCo itself.3 Managers who hire might be routinely frustrated because HR gets to have the first pick in coming up with a list of probable candidates for a position and they are disappointed with the candidates that HR picks. HR however insists that these managers have a narrow view of what counts as a good employee; that indeed, it is HR which has the domain-nonspecific expertise that allows them to go beyond specific manager demands like technical skills to think about other facets that make a good MultiCo employee.
This dispute between the two groups of domain experts does not die out once the algorithm enters the picture. Now it centers around who gets to shape the algorithm the most. And it’s clear that it’s the HR professionals who got to serve as the voice of MultiCo and be the key gatekeepers of “domain expertise” into the algorithm.
Now, let’s think about (b). When I talked about NeuroYou in this post, I bluntly referred to the people working at NeuroYou as “data scientists.” But if you look at the paper, NeuroYou itself is an organization with a variety of roles. Here is the table from the paper listing the teams at NeuroYou.
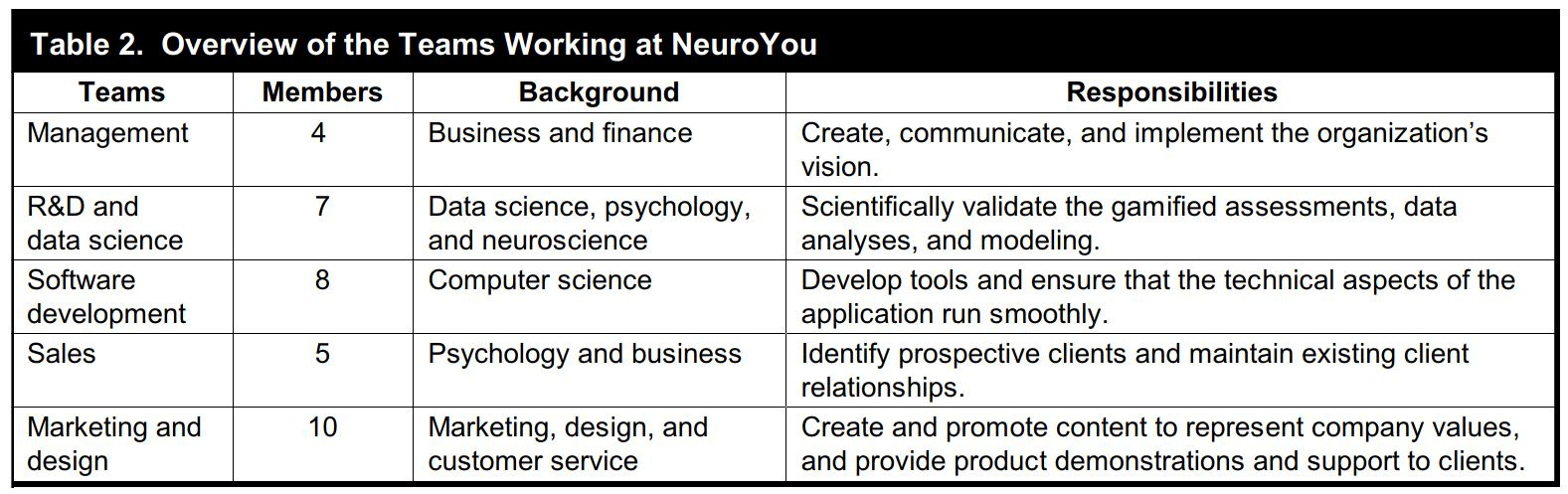
There are at least four kinds of backgrounds of NeuroYou workers who are not in management, sales or marketing: data science, psychology, neuroscience, and computer science. Once again, going beyond what’s in the paper, is it possible that there are conflicts going on between people in these backgrounds? Almost certainly. But does it matter?
The authors describe NeuroYou as a “ML [machine learning] vendor” and “a leader in the market of predictive people analytics” that “offers a wide range of ML-supported functionalities.” But here is the kind of product NeuroYou is selling:
Unlike traditional selection methods that rely on self-reported data, such as questionnaires and CVs, these games simulate situations where participants’ personalities and behavior are supposed to be reflected. For example, one game asks candidates to inflate a digital balloon with air in exchange for a reward. Since each inflation also presents a risk of bursting the balloon and losing the rewards gained, the game identifies a person’s propensity for risk-taking behavior. Another game measures people’s ability to understand emotions.
When you think about it, NeuroYou is a company that is selling a psychological product. It almost doesn’t matter whether the people who develop the product call themselves “data scientists,” “psychologists,” “programmers,” or “computer scientists.”
If anything is being empowered here, it is psychology (as opposed to psychologists). As the historian Nikolas Rose has put it, “the social consequences of psychology are not the same as the social consequences of psychologists.” Psychology, Rose argues, is “generous” in “how it lends itself freely to other[s]” such as managers, HR professionals, social workers, management consultants, and many others who use it as “justification and guide to action”; now one might add “data scientists” and “ML developers” to this list. Psychology, in this definition, is more than psychologists; it is a way of thinking, a style of reasoning that can be taken up by others. And irrespective of whether it is psychologists who develop the algorithm at NeuroYou or data scientists, it is almost certainly psychology that is being empowered here.
Conclusion
This has been a somewhat long-winded post. The point of these series of posts is to try to arrive at a generalized understanding of how data science is changing the world by looking at as wide a variety of cases as possible. And so, one shouldn’t reach a conclusion by analyzing just one case. But still, the case-study of NeuroYou and MultiCo suggests that any generalized understanding of the effects of data science on domain expertise has to consider the following issues:
What is the organizational relationship between the data scientists and domain experts? Domain experts who are clients (HR professionals) are in significant positions of power compared to data scientists than domain experts who are users (hiring managers) or just purveyors of abstract knowledge (psychologists).
What about contests between putative domain experts? There are many domain experts in any activity and the use of algorithms and/or data science might be a way for one group of domain experts to gain the upper hand. It is also important to think about who the “relevant” domain experts are and what is the nature of their expertise. Experts who possess meta-expertise seem to be the ones most likely to cooperate with data scientists but also feel threatened by them.
In my next post in this series, I will take a look at the articles by David Ribes and colleagues from UW who have written some of the most sustained explorations of the logic of domains and of data science.
This capsule summary is mostly an American history and the paper I summarized in this post is mostly about Europe but it’s safe to say that practices originating in the US often get adopted and exported to other countries.
The term also occurs in Robert Evans and Harry Collins book “Rethinking Expertise.” However, Pasquale uses it in a very different way and means something quite different than Evans and Collins. I hope to discuss this concept a lot more in a future post.
There is nothing to indicate that in the paper but the authors main informants in MultiCo seem to be people who work in HR-related tasks so it’s possible that this was just not relevant for the fieldwork.